Data -> Information -> Knowledge
데이터 자체에는 의미가 없다.
-10 가지고는 아무것도 알 수 없다. => 서울 겨울 -10, 데이터를 processing 하면 Information이 돼..
대한민국의 평균 기온은 -3도야.. -> 30년 역사상 가장 추운 겨울이야 (정보)
information = processing ( data ) information을 통해 의사 결정을 함 ( decision )
knowledge는 information 을 바탕으로 누적된 경험을 통해 value를 이끌어 내는 것
** SQL 실습

3번의 마지막 CASE
4번은 조회되지 않는다. SQL 명령어는 대소문자 구분을 하지 않지만, 데이터는 반드시 대소문자를 구분하여 표기
즉, JOB = 'MANAGER' 로 해야 한다.
ex) 네이버에서 로그인할 때 대소문자를 구분하여 입력해야 로그인이 돼..
6번의 경우 1=1 이므로 TRUE를 리턴함.
1=2 아니므로 FALSE 리턴함.
3번의 마지막 CASE
SELECT DEPTNO,SAL,EMPNO,ENAME FROM EMP WHERE DEPTNO = 10 OR SAL > 2000; 의 경우

중복은 제외하고 결과를 반환하는 것을 알 수 있었다.

6번의 1=1 인 경우 TRUE를 리턴하므로 SELECT * FROM EMP 와 같은 결과를 리턴하는 것을 알 수 있다.
이와 달리, 1=2의 경우는 다음과 같다.

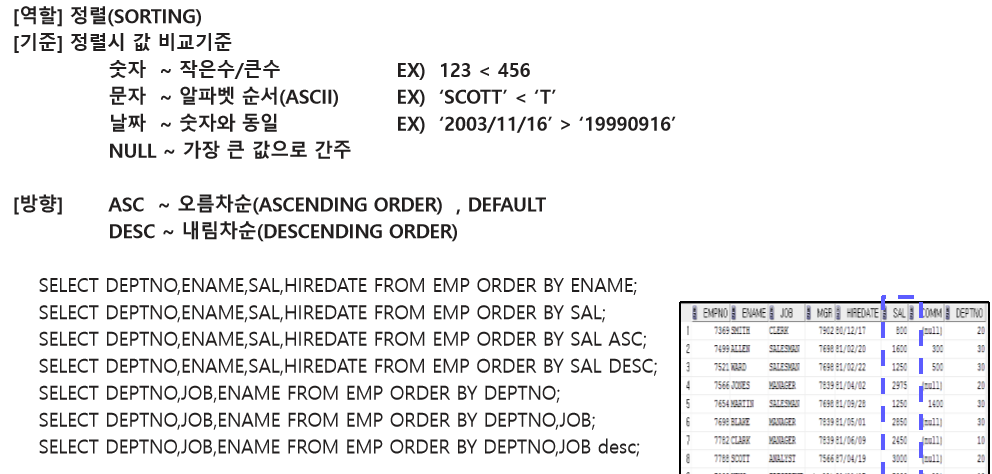
3번째의 경우, SELECT DEPTNO,ENAME,SAL,HIREDATE FROM EMP ORDER BY SAL ASC;
ORDER BY 는 정렬의 기준(칼럼명) 을 설정하고, ASC는 정렬의 방향을 의미 [ ] → OPTIONAL 선택사항
2번 SQL과 3번 SQL은 결과가 동일하다.
1번의 경우 이름을 기준으로 결과를 조회하겠다.
6번의 경우, 7번의 경우 정렬의 기준이 2개이다.
정렬의 첫번째 기준은 DEPTNO 이고 두번째 기준은 JOB
우선 DEPTNO를 기준으로 정렬을 하고 같은 DEPTNO는 JOB을 기준으로 정렬

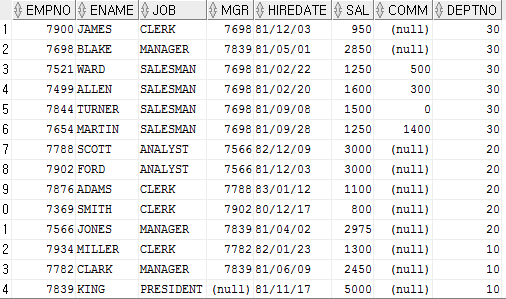
DEPTNO 를 내림차순의 기준으로 정렬을 한 후, 직업을 기준으로 ASC 으로 정렬을 한 후 출력을 한다..
여기서 중요한 것은 ASC, DESC를 모두 표시하여 SQL의 명확성을 높여 작성한다.
** NULL, 존재하지 않는!!
select * from emp order by comm desc;
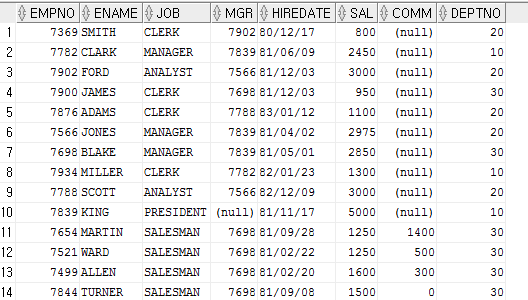
null 인 경우 가장 큰 값으로 간주. 가장 큰 값은 아니다. 왜냐하면 존재하지 않는 것이므로!!
null 은 제어가 안돼, 비교가 안돼, 연산이 불가능 해 → 제 비 연

3번의 경우 DISTINCT 연산자가 영향을 미치는 범위는 ? 이하의 모든 컬럼에 영향을 미침.
(조합의 순서쌍은 중복된 것이 없다)
급여를 가장 많이 받는 사람의 순서로 정렬을 한다...
데이터를 모두 조회해야 정렬이 된다. → 데이터 수가 늘어나면 ORDER BY 굉장히 무거운 연산이 될 수 있음
SELECT * FROM CUSTOMER ORDER BY ADDRESS1 DESC;

조회했을 때 정렬을 할 때 너무 많은 데이터가 한꺼번에 요청을 보내면 다음과 같은 에러가 난다.
TEMP 정렬은 메모리가 아닌 디스크에서 관리하기 때문이다.
적은 양의 데이터는 메모리에서 정렬하기 때문에 속도가 빠르지만, 많은 양의 데이터를 정렬할 경우 디스크 공간을 빌려쓰므로 시간이 오래 걸리게 된다.
여기서 얻은 교훈 : 전체 데이터를 모두 조회해야 정렬이 된다.

1번의 경우 해당 컬럼을 기준으로 그루핑을 해라!
-> 부서별 근무자 수가 나옴
SCOTT.EMP는 [스키마.]EMP
GROUP BY 된 결과는 정렬이 되지 않는다. 그러므로 GROUP BY _____ 한 후 ORDER BY ASC
DESC
를 반드시 해주어야 한다.
- 용어설명
SCOTT.EMP는 [스키마.]EMP
GROUP BY 의 알고리즘 9i, 10g 이 용어가 뭐지? 어떤 원리로 되는거지 ? 이것만 쓰면 돼
DISTINCT 연산자 알고리즘 ORACLE DBMS는 어떻게 처리하는거야? 크게 한 번 바뀐적이 있는데 그거 중심으로
클러스터링, 미러링의 정의, Semantic
인스턴스는 메모리와 프로세스로 이루어져 있음, 데이터베이스는 연관된 데이터의 집합
모든 서버에는 리스너라는 프로세스가 있음. 이 프로세스는 접속 요청에 대한 귀를 기울이고 있음.
오라클의 메모리는 크게 다섯 개의 영역으로 되어 있음. (SGA)
SQL developer를 이용해서 DBMS로 쿼리를 보내면 다음과 같은 과정이 DBMS 내부에서는 이루어짐.

data buffer cache 오른쪽에는 read log buffer 캐시가 있음. read log buffer 캐시에서는 데이터의 update log를 관리함.
data buffer cache 왼쪽에는 shared pool이 있음
사용자가 IP를 입력하면 기기를 찾아가고, 포트 번호를 통해 리스너에 접근. 그리고 클라이언트에서 입력한 SID 값을 통해 하드웨어 내부에 설치된 DBMS에서 접근!
PGA는 서버 프로세스를 만들고 메모리를 할당한다. PGA 메모리 내부에 세션 정보가 있음
클라에서 sql이 오면 3단계를 거쳐 진행한다.
** SQL
1. Parsing (컴파일하는 단계)
ㄱ. Syntax check 문법적으로 맞았는지
ㄴ. Semantic check 의미론적으로 맞았는지
ㄷ. Execution plan 수립 (cpu intensive job)
optimizer에서 실행 계획을 고민함. 옵티마이저는 모든 dbms에 다 있음
2. Execute
3. Fetch
찾은 데이터를 클라이언트에서 가져옴 -> 그러면 우리가 볼 수 있음.
SQL은 대표적인 비절차적 언어이다...
C언어, JAVA는 절차적 언어이다.
절차적 언어 : 처리 순서, 처리 방법을 명시 (HOW)
비절차적이란 ? 절차가 없다 -> 처리 순서와 처리 방법이 없다
내가 필요한 것은 무엇이야 WHAT 을 정의.
절차를 고민하는 것은 서버가 한다..
'데이터베이스' 카테고리의 다른 글
| Syntax diagram - SELECT (0) | 2019.05.03 |
|---|---|
| 오라클 과제 (190502) (0) | 2019.05.02 |
| DB, DBMS, RDBMS 에 대한 정의 (0) | 2019.05.01 |
| 오라클 실습 (190501) (0) | 2019.05.01 |
| Connection이란 (0) | 2019.05.01 |


