
PL/SQL 을 잘 쓰면 정말 좋음
함수의 입력값으로 몇개가 들어오는가? 이것이 그룹행 함수와 단일행 함수의 차이점이다.
그룹행 함수? 3번을 보면 입력을 14개 받아서 하나의 결과를 낸다.
단일행 함수? 입력을 하나 받아서 하나를 리턴한다.
*** Full table SCAN
데이터를 처음부터 끝까지 다 보아야만 결과가 나옴.
(그룹행함수의 특성임) - 데이터양이 많아졌을때 무거운 연산이 될 수 있음

** 많이 쓰이는 것들입니당
SUBSTR 부분 문자 추출 함수
LENGTH 문자열의 길이를 리턴
REPLACE 치환하는 함수 -> SQL 명령문은 대소문자를 구분하지 않지만, 데이터는 대소문자를 구분한다.
instr 'A'의 위치가 몇번째야? 라는 의미이다.
trim

7번에서 2번의 경우 trim할 문자를 지정할 수 있음.
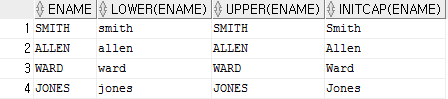
1번의 경우
select ename, lower(ename), upper(ename), initcap(ename) from emp;
2번의 경우
select ename, substr(ename,1,3), substr(ename,4), substr(ename,-3,2) from emp;

3번의 경우

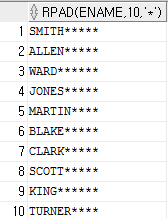
4번의 경우
select rpad(ename,10,'*') from emp;
5번의 경우
select ename, replace(ename,'S','s') from emp;

7번의 경우
select ltrim(' 대한민국 '), rtrim(' 대한민국 ') from dual;


TRUNC = 트렁케이트라고 읽는다.
round, trunc
45.923,2 여기서 2는 나는 소숫점 자리 아래 두자리까지만 관심있게 보겠다 라는 의미.
그 이하에서 무언가를 해라라는 의미이다.
9번의 경우
select round(45.923,2), round(45.923,1), round(45.923,0), round(45.923), round(45.923,-1) from dual;

위치에 따른 값이 다음과 같이 할당될 수 있음.
10번의 경우
select trunc(45.923,2), trunc(45.923,1), trunc(45.923,0), trunc(45.923), trunc(45.923,-1) from dual;

argument는 내가 관심있게 볼 자릿수라는 의미이다.

Date는 날짜와 시간 정보를 가지고 있음. 그리고 고정된 7byte의 길이를 가진다.
내부에서는 숫자로 저장이 되고, 외부에 표현될 때는 문자처럼 보인다.
내부에 저장될 때 숫자 형태로 저장이 된다 그러므로 연산이 가능하다는 유추가 ㅇㅇㅇ
date 안에 연,월,일,시,분,초가 포함되어 있다, 그리고 date는 연산이 가능하다 왜냐하면
숫자 형태로 저장이 되기 때문이다.
이 두 가지는 반드시 기억하고 있자!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
시간이 안보이는 이유는 ? 날짜를 표시하는 포맷 때문이다.
yy yy mm dd:hh24 mi ss
20 19 05 08 14 21 36
두 개의 숫자가 하나의 byte에 저장이 된다.
한 바이트가 두 개의 digit을 저장하는 것을 가리켜 packed decimal 이라고 함
숫자도 이와 같은 형태로 packed decimal 형태로 저장이 됩니다!
4번의 경우
ALTER SESSION의 경우 사용자가 로그아웃하면 세션이 날아감
5번을 약간 변경해서 실행할 것임.
5) Alter session
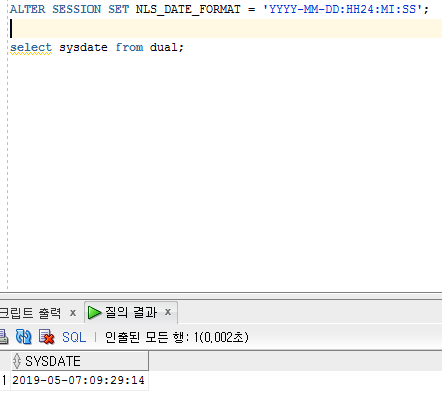
다른 세션으로 로그인한 경우, 다음

과 같이 원래의 출력값으로 나오는 것을 확인할 수 있다.
이는 두 번의 커넥션을 통해 다른 세션으로 로그인한 경우이므로 다르게 나온다.
NLS의 뜻은 자국의 표현 방식 포맷을 지원한다는 의미임.
즉 내부에 저장되는 DATE의 형태와 외부로 표현되는 DATE의 형태는 다르다.
내부에 저장되는 방식은 언제 어디서나 모두 같음.
하지만 외부로 표현될 때는 개발하는 국가에서 사용하는 형태로 표현할 수 있음.

ALTER SESSION SET NLS_DATE_FORMAT='DD-MON-YY HH24:MI:SS';
SELECT SYSDATE FROM DUAL;
여기서 월을 보면 MAY라고 나오지 않고 5월이라고 나오는 것을 확인할 수 있다.
왜?
하지만 다른 워크시트는 같은 세션임을 알 수 있다.
**** 시험문제 - 커넥션과 세션을 설명하고 그리시오.
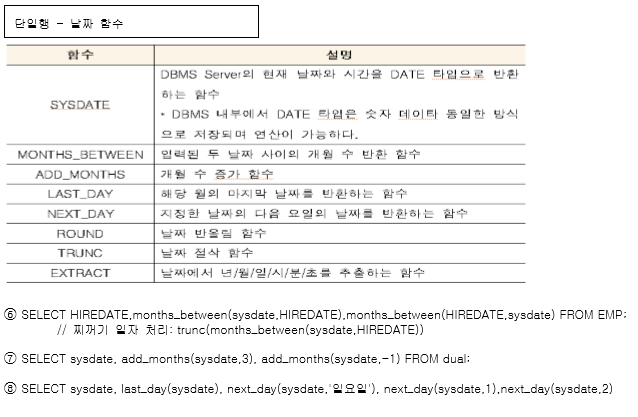
SYSDATE, LAST_DAY, NEXT_DAY, ROUND, TRUNC는 자주 써요!
8번의 경우 - last_day 해당 달의 마지막 날은 몇일이냐 ? 라는 의미
next_day

Root - system -> manager
- sys -> owner
집합 연산자는 데이터의 수직적 결합
JOIN 연산자는 데이터의 수평적 결합
interactive sql 우리가 지금 dbms와 상호작용하기 위해 사용하는 sql
embedded sql
host language (c언어, 자바 등등) 내부에 들어 있는 sql이 embedded sql이다.
바로 임베디드 sql로 개발하는 것이 빠를까
interactive sql을 만든후 임베디드 sql로 변형하는 것이 빠를까 ?
가장 먼저 interactive sql을 개발하고, embedded 화하는 것이 빠르다.
에러의 원인이 host language에 의한 에러인 것인지 sql 에러인지 모름
그러므로 interactive를 통해 sql이 문제가 없음을 증명하고 시작하는 것이 빠름.
개발의 생산성, 능률이 더 좋다..
ROWID 는 레코드에 부여된 주소값이다. - 식별자 -
현실 세계에서 페이지 번호에 해당한다.
식별자는 -> NOT NULL
1. 최소성
2. 고유성
3. 존재성
4. 불변성
인덱스 스캔 - 목차를 보고 찾는 것
풀 테이블 스캔 - 처음부터 끝까지 모두 조회
이 포맷 암기 후 설명 (숙제)

select to_char(sysdate,'DDD'), to_char(sysdate,'DD'), to_char(sysdate,'D') FROM DUAL;

'DD' 는 5월부터 지난 일의 수

5번은 정말 많이 사용될 것입니당!
ALTER SESSION SET NLS_LANGUAGE = 'AMERICAN';
로 바꾼 후 위의 실습을 진행

세션을 다음과 같이 바꾼 후 실습을 진행하면 5월이 MAY로 변경된 것을 확인할 수 있음.
4번의 LENGTH(TO_CHAR(123456,'999999')
의 경우 7을 리턴함. 앞에 부호를 위한 공백문자가 삽입되었기 때문에, 6을 리턴하는 것이 아니라, 7을 리턴한다.
fm 은 공백문자를 없애는 것이기 때문에 6이 리턴 돼 !
5번의 경우
포맷은 항상 대상의 숫자보다 커야한다.

8번의 MIN, MAX는 문자, 정수 등의 모든 값을 구할 수 있다.
날짜의 최대 최소도 숫자와 동일하다. 숫자의 크다 작다와 같음
9번의 경우
count(*) 테이블에 저장된 레코드의 갯수를 구하는 것
count(empno) empno 칼럼에 있는 데이터의 갯수
레코드의 갯수와 특정 칼럼의 수와 다를 수 있으나, empno에는 NOT NULL 이므로 (제약사항)
이럴 경우에는 항상 같다
그룹행 함수는 NULL을 무시한다.
10번의 경우
COUNT(ALL JOB) 안씁니다.
SELECT COUNT(*), COUNT(EMPNO), COUNT(MGR), COUNT(COMM) FROM EMP;
COUNT는 NULL을 리턴하는 것이 아니라, 총 갯수를 리턴해준다.
11번 정말 중요
SELECT COUNT(*),SUM(COMM),SUM(COMM)/COUNT(*),AVG(COMM),SUM(COMM)/COUNT(COMM) FROM EMP;

COUNT(*) 의 경우 14가 리턴되는데 COMM 은 NULL을 가지므로 그냥 나눈다고해서 평균 COMM이 아님.
AVG(COMM) 의 경우 일치
SUM(COMM)/COUNT(COMM) 의 경우 일치
13번
SELECT
SUM(NVL(COMM,0)) AS SUM_COMM1,
SUM(COMM) AS SUM_COMM2,
NVL(SUM(COMM),0) AS SUM_COMM3
FROM EMP;

1번의 경우 NULL 값을 0으로 치환하고 SUM 한 것 -> 1400만명의 직원이 있을 경우, NVL 함수를 1400만번 호출한 후...
(가장 비효율적)
2번의 경우 가장 효율적! NVL 연산이 필요 없음
3번의 경우 NVL(SUM(COMM),0)
- 항상 데이터가 많아졌을 때 어떻게 될 지 항상 생각해주어야한다

ORDER BY 는 SELECT SYNTAX 중 가장 마지막에 위치하고 가장 마지막에 실행된다.
10번 부서에 3명 근무하고, 20번 부서에 5명 ... 데이터를 수직 X 수평 O
-> COUNT, DECODE를 잘 활용하면 구할 수 있음

GROUP BY의 결과에 대한 조건문이 HAVING임!!!!!!!!!!!!!!!!!!!!!
WHERE과 HAVING의 공통점 : 조건절 (WHERE은 TABLE에 대한 조건절) / (HAVING은 GROUP BY에 대한 조건절)
차이점 :
6번의 것
순서
FROM - WHERE - GROUP BY - HAVING - SELECT - ORDER BY
HASH 팀이 할 것임
- 사전적의미
- 역할 & 사례 (1) 암호화 (2) DAM(Direct Access Method) - 자료구조! (3) 무결성(Integrity)
- 특징 (1) 고정길이 (2) 충돌회피 (3) 단방향
- Hash 함수 (?)
'데이터베이스' 카테고리의 다른 글
| 오라클과제 (190507) (0) | 2019.05.07 |
|---|---|
| 오라클실습 (JOIN) (0) | 2019.05.07 |
| ROWNUM (0) | 2019.05.03 |
| 널 (null), 디코드 (decode), 케이스 (case) (0) | 2019.05.03 |
| group by, distinct, schema, 시분초 (0) | 2019.05.03 |



